回顾分治算法
分治算法的英文名叫做“divide and conquer”,它的意思是将一块领土分解为若干块小部分,然后一块块的占领征服,让它们彼此异化。这就是英国人的军事策略,但我们今天要看的是算法。
如前所述,分治算法有3步,在上一篇中已有介绍,它们对应的英文名分别是:divide、conquer、combine。
接下来我们通过多个小算法来深化对分治算法的理解。
二分查找算法
问题描述:在已排序的数组A中查找是否存在数字n。
1)分:取得数组A中的中间数,并将其与n比较
2)治:假设数组为递增数组,若n比中间数小,则在数组左半部分继续递归查找执行“分”步骤 3)组合:由于在数组A中找到n后便直接返回了,因此这一步就无足轻重了平方算法
问题描述:计算x的n次方
我们有原始算法:用x乘以x,再乘以x,再乘以x,一直有n个x相乘
这样一来算法的复杂度就是Θ(n)。
分治算法:我们可以将n一分为二,于是,
当n为奇数时,xn=x(n−1)/2∗x(n−1)/2∗x
当x为偶数时,xn=xn/2∗xn/2
此时的复杂度就变成了Θ(lgn)。
斐波那契数
斐波那契数的定义如下:
当然,可以直接用递归来求解,但是这样一来花费的时间就是指数级的Ω(Φn),Φ为黄金分割数。
然后我们可以更进一步让其为多项式时间。
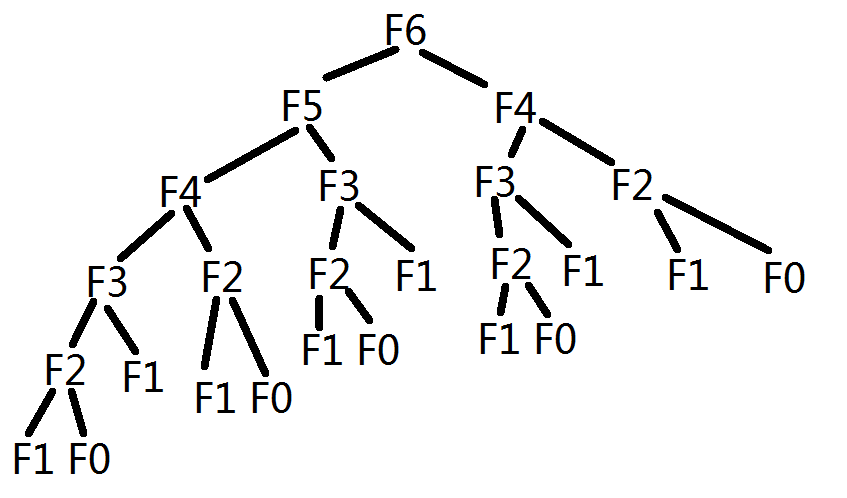
上面这幅图虽然比较简略,在求n为6时的斐波那契数,我们却求解了3次F3,F1和F0的求解次数则更多了,我们完全可以让其只求解一次。
对此,还有一个计算公式:
Fi=Φi−Φ¯i(√5)
其中Φ¯¯¯是黄金分割率Φ的共轭数。
然后这个公式只存在与理论中,在当今计算机中仍旧无法计算,因为我们只能使用浮点型,而浮点型都有一定的精度,最后计算的时候铁定了会丢失一些精度的。
下面再介绍一种平方递归算法:

一时忘了矩阵怎么计算成绩,感谢 相助。
最大子数组问题
最近有一个比较火的话题,股票,那么这一篇就由此引入来进一步学习分治算法。在上一篇博客中已经对插入排序和归并排序做了初步的介绍,大家可以看看:
当然了,这篇博客主要用来介绍算法而非讲解股票,所以这里已经有了股票的价格,如下所示。
| 天 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 股票价格 | 50 | 57 | 65 | 75 | 67 | 60 | 54 | 51 | 48 | 44 | 47 | 43 | 56 | 64 | 71 | 65 | 61 | 73 | 70 |
| 价格波动 | 0 | 7 | 8 | 18 | -8 | -7 | -6 | -3 | -3 | -4 | 3 | -4 | 13 | 10 | 7 | -6 | -4 | 12 | -3 |
价格表已经有了问题是从哪一天买进、哪一天卖出会使得收益最高呢?你可以认为在价格最低的时候买入,在价格最高的时候卖出,这是对的,但不一定任何时候都适用。在这里的价格表中,股票价格最高的时候是第3天、价格最低的时候是第11天,怎么办?让时间反向行驶?
就像我以前参加学校里的程序设计竞赛时一样,也可以用多个for循环不断的进行比较。这里就是将每对可能的买进和卖出日期进行组合,只要卖出日期在买进日期之前就好,这样在18天中就有C218种日期组合,也可以写成(182)。因此对于n天,就有(n2)种组合,而(n2)=Θ(n2),另外处理每对日期所花费的时间至少也是常量,因此这种方法的运行时间为Ω(n2)。
然后,我们在学习算法,自然要以算法的角度来看这个问题。比起股票价格,我们更应该关注价格波动。如果将这个波动定义为数组A,那么问题就转换为寻找A的和最大的非空连续子数组。这种连续子数组就是标题中的最大子数组(maximum subarray)。将原表简化如下:
| 数组 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 7 | 8 | 18 | -8 | -7 | -6 | -3 | -3 | -4 | 3 | -4 | 13 | 10 | 7 | -6 | -4 | 12 | -3 |
在这个算法中,常常被说成是“一个最大子数组”而不是“最大子数组”,因为可能有多个子数组达到最大和。
只有当数组中包含负数时,最大子数组问题才有意义。如果所有数组元素都是非负的,最大子数组问题没有任何难度,因为整个数组的和肯定是最大的。
使用分治思想解决问题
我们将实际问题转换为算法问题,在这里也就是要寻找子数组A[low...high]的最大子数组。分治思想意味着将问题一分为二,这里就需要找到数组的中间位置mid,然后考虑求解2个子数组A[low...mid]和A[mid+1...high]。而A[low...high]的任何连续子数组A[i...j]所处的位置必然是以下情况之一:
1)完全位于子数组A[low...mid]中,因此low≤i≤j≤mid;
2)完全位于子数组A[mid+1...high]中,因此mid<i≤j≤high; 3)跨越中点mid,因此low≤i≤mid≤j≤high。A[low...high]的一个最大子数组所处的位置必然是这三种情况之一,而且还是这三种情况中所有子数组中和最大者。对于第1种和第2种情况我们可以通过递归来求解最大子数组,对于第三种情况我们可以通过下面伪代码所示来求解。
FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)1 left-sum = -100002 sum = 03 for i = mid downto low4 sum = sum + A[i]5 if sum > left-sum6 left-sum = sum7 max-left = i8 right-sum = -100009 sum = 010 for j = mid + 1 to high11 sum = sum + A[i]12 if sum > right-sum13 right-sum = sum14 max-right = j15 return (max-left, max-right, left-sum + right-sum)
下面是以上程序的一个简易程序。
#include#include using namespace std;int const n=18;int A[n]={ 7,8,18,-8,-7,-6,-3,-3,-4,3,-4,13,10,7,-6,-4,12,-3};int B[3];int low,high,mid;int max_left,max_right;int sum;void find_max_crossing_subarray(int A[],int low,int mid,int high);int main(){ find_max_crossing_subarray(A,0,7,15); for(int i=0;i<3;i++) { printf("%d ",B[i]); } return 0;}void find_max_crossing_subarray(int A[],int low,int mid,int high){ int left_sum=-10000; sum=0; for(int i=mid;i>=low;i--) { sum=sum+A[i]; if(sum>left_sum) { left_sum=sum; max_left=i; } } int right_sum=-10000; sum=0; for(int j=mid+1;j<=high;j++) { sum=sum+A[j]; if(sum>right_sum) { right_sum=sum; max_right=j; } } B[0]=max_left; B[1]=max_right; B[2]=left_sum+right_sum;}
如果子数组A[low...high]包含n个元素(即n=high−low+1),则调用FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)花费Θ(n)时间。而上面的两个for循环都次迭代都会花费Θ(1)时间,每个for循环都执行了mid−low+1(或high−mid)次迭代,因此总循环的迭代次数为:
(mid−low+1)+(high−mid)=high−low+1=n
可以看出上面的算法所花费的时间是线性的,这样我们就可以来求解最大子数组问题的分治算法的伪代码咯:
FIND-MAXIMUM-SUBARRAY(A,low,high)1 if high==low2 return (low,high,A[low])4 (left-low,left-high,left-sum)=FIND-MAXIMUM-SUBARRAY(A,low,mid)5 (right-low,right-high,right-sum)=FIND-MAXIMUM-SUBARRAY(A,mid+1,high)6 (cross-low,cross-high,cross-sum)=FIND-MAX-CROSSING-SUBARRAY(A,low,mid,high)7 if left-sum>=right-sum and left-sum>=cross-sum) return (left-low,left-high,left-sum)8 else if(right-sum>=left-sum and right-sum>=cross-sum) return (right-low,right-high,right-sum)9 else return (cross-low,cross-high,cross-sum)
只要初始调用FIND-MAXIMUM-SUBARRAY(A,1,A.length)就可以求出A[1...n]的最大子数组了。
分析分治算法和渐近记号中的省略问题
下面我们又来使用递归式来求解前面的递归过程FIND-MAXIMUM-SUBARRAY的运行时间了,就像上一篇分析归并排序那样,对问题进行简化,假设原问题的规模为2的幂,这样所有子数组的规模均为整数。
第1行花费常量时间。当n=1时,直接在第二行return后跳出函数,因此
T(1)=Θ(1)
当n>1时,为递归情况。第1行和第3行都花费常量时间,第4行和第5行求解的子问题均为n/2个元素的子数组,因此每个子问题的求解总运行时间增加了2T(n/2)。第6行调用FIND-MAX-CROSSING-SUBARRAY花费Θ(n)时间,第7行花费Θ(1)时间,因此总时间为
T(n)=Θ(1)+2T(n/2)+Θ(n)+Θ(1)=2T(n/2)+Θ(n)
在上面的步骤中,将Θ(1)省略掉的作法大家应该都理解吧。
回顾前面n=1的情况,第一行花费了常量时间,第二行同样也花费了常量时间,但这两步花费的总时间却是Θ(1)而非2Θ(1),这是因为在Θ符号中已经包含了常数2在内了。
但是为什么第4行和第5行中却是2Θ(n/2)而非Θ(n/2)时间呢?因为这里是递归呀,这里的因子就决定了递归树种每个结点的孩子个数,因子为2就意味着这是一颗二叉树(也就是每个结点下有2个子节点)。
如果省略了这个因子2会发生什么呢?不要以为就是一个2这么小的数而已哦,后果可严重了,看下图……左侧是一棵4层的树,右侧就是因子为1的树(它已经是线性结构了)。
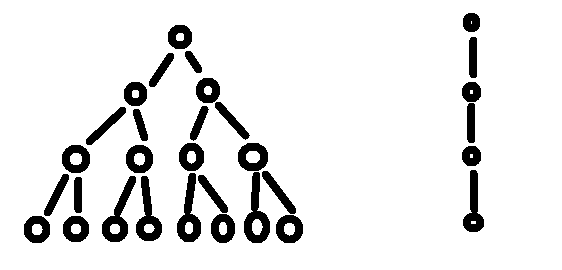
总结来说,渐近记号都包含了常量因子,但递归符号却不包含它们。
借助递归树求解递归式
前面我们已经看到了递归式,也看到了递归树,那么如何借助递归树来求解递归式呢?接下来就来看看吧。
在递归树中,每个结点都表示一个单一问题的代价,子问题对应某次递归函数调用。
通过对树中每层的代价进行求和,就可以得到每层的代价;然后将所有层的代价求和,就可以得要到所有层次的递归调用的总代价。
我们通常用递归树来得出一个较好的猜测结果,然后用代入法来证明猜测是否正确。但是通过递归树来得到结果时,不可避免的要忍受一些”不精确“,得在稍后才能验证猜测是否正确。
因为下面的示例图太难用键盘敲出来了,我就用了手写,希望大家不介意。
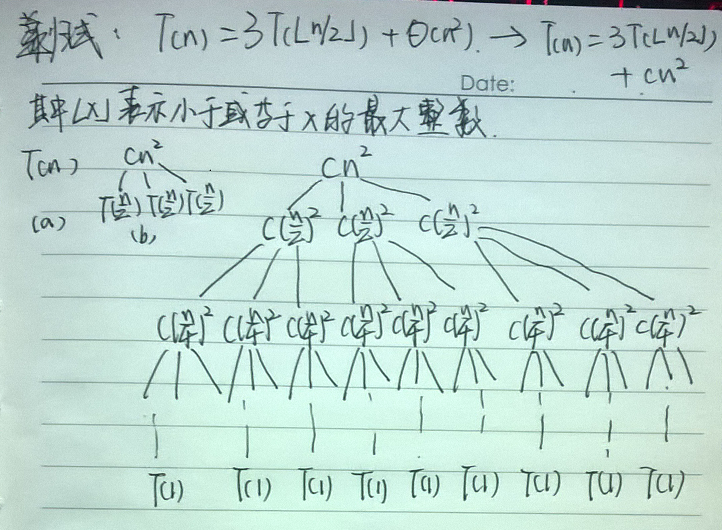
如下所示,有一个递归式,我们要借助它的递归树来求解最终的结果。前面所说的忍受“不精确”这里就有2点:
1)我们要关注的更应该是解的上界,因为我们知道舍入对求解递归式没有影响,因此可以将Θ(n2)写成cn2,且为该递归式创建了如下递归树。
2)我们还将n假定为2的幂,这样所有子问题的规模均为正数。
图a所示的是T(n),在图b中则得到了一步扩展的机会。它是如何分裂的呢?递归式的系数为3,因此有3个子结点;n被分为2部分,因此每个结点的耗时为T(n/2)。图c所示的则是更加进一步的扩展,且直到最后的终点。
这棵树有多高(深)呢?
我们发现对于深度为i的结点,相应的规模为n/2i。因此当n/2i=1时,也就意味着等式i=log2n成立,此时子问题的规模为1。因此这个递归树有log2n+1层。那为什么不是log2n层呢?因为深度从0开始,也就是(0,1,2,...,log2n)。
有了深度还需要计算每一层的代价。其中每层的结点数都是上一层的3倍,因此深度为i的结点数为3i。而每一层的规模都是上一层的1/4,所以对于i=0,1,2,...,log4n−1,深度为i的每个结点的代价为c(n/2i)2。
因此对于i=0,1,2,...,log4n−1,深度为i的所有结点的总代价为(3i)∗(c(n/2i)2),也就是3ic(n/2i)2。
递归树的最底层深度为log2n,它有3log2n=nlog23个结点,每个结点的代价为T(1),总代价就是nlog23T(1),假定T(1)为常量,即为Θ(nlog23)。
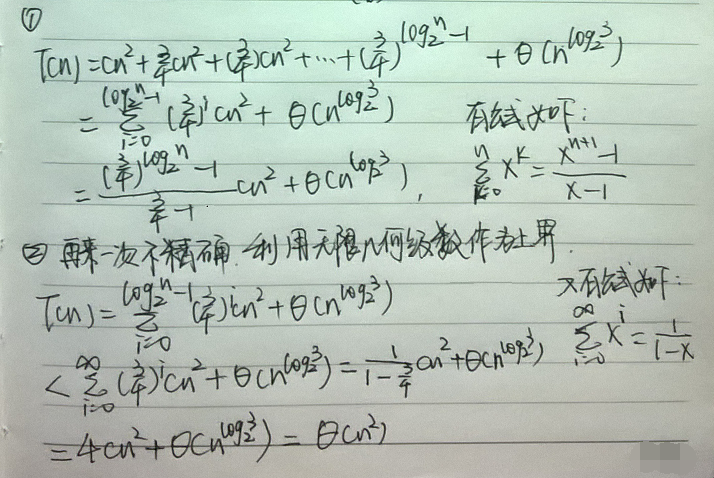
至于这最后的4c为什么可以直接省略掉,如上一节所说的,渐近记号都包含了常量因子。因此猜测T(n)=Θ(n2)。在这个示例中,cn2的系数形成了一个递减几何级数。由于根结点对总代价的贡献为cn2,所以根结点的代价占总代价的一个常量比例,也就是说,根结点的代价支配了整棵树的总代价。

不知道大家看不看得清,上面的两行文字是“我们要证的是T(n)≤dn2对某个常量d>0成立,使用常量c>0“和”当d≥4c时,最后一步成立。
写一篇博客本来不会这么漫长的,可是这是算法,结果就不一样了……
感谢您的访问,希望对您有所帮助。 欢迎大家关注、收藏以及评论。
为使本文得到斧正和提问,转载请注明出处: